Student Advice: Should I Go to Graduate School? If So, Where Should I Go?
[This article was first posted on January 18, 2014 at The Political Methodologist.]
It’s that time of year again: prospective graduate students are applying to PhD programs, perhaps being wooed by a few different schools, and choosing whether to accept the invitation (and which invitation to accept). Typically, at least in the United States, the prospective student must make a choice by April 15th.
So, here’s a topic for undergraduates thinking about entering a PhD program this Fall: should you go to graduate school? And if you receive more than one offer, which should you choose?
Well, I’m not sure there are right answers for these questions that apply to everyone, in all disciplines. And if there were correct answers, I’m not sure I’d be the one to have them. I’m not an expert. But I’ve been in academia for a few years at PhD-granting institutions, and there are some things that I think that everyone (regardless of field) should think about before they say “yes.” If others disagree or think that I’ve left out some important considerations, I hope they’ll add comments to this post!
In my opinion, the first and most important thing to remember is that the choice to enter a PhD program is a not just a scholarly decision, but is also an economic decision that can have extremely significant consequences for your future. I believe that it is appropriate to think about this decision the way you would think about whether to accept a job offer. Specifically, I think the following questions should be foremost in your mind:
- Is it possible to live a safe, comfortable life on the stipend I am being offered, given the local cost of living, while I am in graduate school? Will I have to take out loans in order to stay healthy and subsist at a reasonable standard of living? How much work outside of my own studies (teaching, TAing, RAing, administrative work) will I have to do to earn that stipend?
- What are my chances of successfully completing this program and earning a PhD, based on the past performance of other students in this program?
- After I finish the program, what job opportunities will be available? How many PhD students who finish the program get the kind of job that I want to have? What happens to those who don’t get that job, and would I be happy with what they’re doing?
The answers to these questions can vary widely across academic disciplines, across different PhD programs at different schools inside of a discipline, and even from person to person inside of a single PhD program!
Stipend and Workload
When I started graduate school in 2003, I knew graduate students in other fields making around $6,400 per year (that’s about $533 a month) with no health insurance coverage; they were required to teach two courses per year starting the day they arrived on campus. In another field, students taught three courses a year for a little under $10,000 (again, with no benefits). Meanwhile, some students on a fellowship were making $17,000 a year with benefits and had no teaching duties in their first two years (if ever), with the opportunity to make more through summer teaching. Students in other departments made still more.
Needless to say, the difference between $6,000 for teaching two courses and $17,000 a year for (at most) some RA work is enormous in terms of physical and psychological health, basic nutrition, and life satisfaction.
If you are offered a stipend that is too small to live on, or no stipend at all, think carefully before you accept. It is not typical to require graduate students to work for less than a living wage. Of course, one should never expect to make as much being in school as one would make in a full-time job (and tuition waivers should be considered a part of the pay). But viable PhD programs are capable of paying their students enough to live on in exchange for their teaching and research assistance. If someone tells you that making little or nothing is normal for graduate students in your field, it probably implies something very important about what you can expect in the future from this career. Consider going to a different school, choosing a different field of study, or applying for jobs with your undergraduate degree. You can find out more about the variation in graduate stipends, both between schools in the same discipline and between different disciplines, by looking at this survey of stipend data.
Completion Rate
Any graduate program should be able to offer you hard numbers on how many students it admits every year and (on average) how many of those students earn their PhD. You should always ask to see these numbers and be very skeptical of attending a school if you are only offered vague impressions, or are told that “the good students” finish.
For your part, when you get these numbers, I believe that you should make your decision assuming that you will be an average student in the program and act accordingly. I recommend that you not assume that you will be exceptional, no matter what has happened in the past or what you are told; PhD programs are full of people who were exceptional undergraduate students.
Ideally, a PhD program would also be able to tell you when students typically leave the program; there is a big difference between attriting after one or two years, and lingering for 7-10 years without earning the PhD. Unfortunately, many schools don’t keep track of these numbers. But it might be worth asking the faculty when most students leave the program, and also asking students who are currently in the program about their impressions.
Employment After the Degree
Now here’s the really critical bit: what happens to you after you finish the PhD?
For many students, I suspect that Plan A is to teach and do research as an academic. But the availability of tenure-track jobs varies widely across fields. Before signing up for a PhD program, you should ask for hard numbers about where the program’s PhDs ended up and how long it took them to get there. Above all, and I cannot emphasize this enough, DO NOT ACCEPT ANECDOTAL SUCCESS STORIES such as “we placed Person X at Princeton just last year.” That is great for Person X, but not great for you if there were 12 other PhDs on the market that year and none of them got any tenure-track offers.
The ideal information is a list of the PhDs who were on the market every year or so for the last 5-10 years and what job (if any) they accepted. Ensure that tenure-track jobs are specifically identified; there is a huge difference between a tenure-track job (which is typically permanent), a “visiting Assistant Professorship” (which is typically for 1-3 years and not renewable), and an “Adjunct Professorship” (which is paid by-the-course, often for little money, and not renewable). Also, not all tenure-track jobs are equal; be sure to think about how well these jobs pay and the type of work that they require (e.g., number of classes to teach, service responsibilities, research requirements, etc.). Also, remember that the answer differs not just by discipline, but can also differ by subfield inside of a discipline; the job prospects for a “political methodologist” and a “political theorist/philosopher” are quite different, despite the fact that both are political scientists. There might even be some formal quantitative analysis of a program’s placement record, like this one for political science.
Again, I recommend that you assume you will be the average student and ask yourself: “Would I be OK with this outcome?”
It is equally important to consider what happens if you do not get the academic job that you want; that is, what is your “Plan B”? I recommend specifically asking any program to which you are applying this question. If the answer is that students take adjunct positions to survive, I strongly recommend that you do not join the program. Adjuncting is an extraordinarily difficult path in life, financially and emotionally, and people can get caught doing it for years (or even forever). On the other hand, if the answer is that your PhD will endow you with skills that are highly valued by business or government (or even higher education administration) and that every PhD in your program who does not get a tenure-track job ends up gainfully employed in a rewarding career, you can enter your program with greater confidence. You would never skydive without a reserve parachute; why would you enter a PhD program without a backup career plan?
Things NOT to Consider
Here are some things that I think should not be factors in your decision:
- The prestige of the program, according to your undergraduate professors and/or the US News and World Report. [updated 1/19/2014 19:46 CST] My argument is that one should choose directly based on placement success (where PhD students end up and how many of them are placed) rather than an indirect metric like prestige. If students follow that advice, and prestige confers a placement advantage, they’ll end up in the prestigious places anyway. If placement success is loosely correlated with prestige, my advice will help them avoid the overrated schools and identify some underrated ones. If even the best schools can’t guarantee job success (as in some humanities), it will help them avoid a big mistake.
- Your personal love for or “calling” to the field in question. As many people have pointed out recently, “do what you love” isn’t a sound plan for graduate school. In short, not everything that you love will love you back. As William Pannapacker put it:
We hear the word all the time in discussions of graduate school: “Only go if you love your subject,” which is about the same as saying, “Only do it if you are willing to sacrifice most of your rational economic interests.” You are, arguably, volunteering to subsidize through your labor all of the work that is not defined as “lovable.”
- The fact that you have no other plan for what to do after you complete your undergraduate degree. Unfortunately, entering graduate school might put you into a worse situation than you are already in; you might end up ten years older, deeply indebted, and with even fewer career prospects. Better to figure things out now than to risk making the situation worse.
In summary: getting a PhD can be one of the best decisions of your life, or one of the worst. Either way, it’s a big decision. Don’t make it lightly.
Congratulations, and good luck!
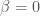 but rather a set of substantively ignorable values at or near zero, as
but rather a set of substantively ignorable values at or near zero, as 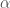 value of the significance test.
value of the significance test.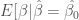 and stat. sig.]. We believe that a conservative estimate of this quantity can be accomplished by simulating many draws of data sets with the structure of the target model but with varying values of
and stat. sig.]. We believe that a conservative estimate of this quantity can be accomplished by simulating many draws of data sets with the structure of the target model but with varying values of  , where these
, where these  estimates can be recovered from properly specified models, then used to form an empirical estimate of
estimates can be recovered from properly specified models, then used to form an empirical estimate of 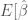 |stat. sig] and
|stat. sig] and  for three values of
for three values of  (we erroneously report this as 200,000 samples in the poster, but in re-checking the code I see that it was only 10,000 samples). We then calculated the proportion of these samples for which the absolute value of
(we erroneously report this as 200,000 samples in the poster, but in re-checking the code I see that it was only 10,000 samples). We then calculated the proportion of these samples for which the absolute value of  is greater than 1.645 (the cutoff for a two-tailed significance test,
is greater than 1.645 (the cutoff for a two-tailed significance test,  ) for values of
) for values of ![\beta\in[-1,3]](https://s0.wp.com/latex.php?latex=%5Cbeta%5Cin%5B-1%2C3%5D&bg=fff&fg=444444&s=0&c=20201002) .
.
![[|\hat{\beta}-\beta|/|\hat{\beta}|]](https://s0.wp.com/latex.php?latex=%5B%7C%5Chat%7B%5Cbeta%7D-%5Cbeta%7C%2F%7C%5Chat%7B%5Cbeta%7D%7C%5D&bg=fff&fg=444444&s=0&c=20201002) , excluding cases we visually identified as outliers. We used three different prior distributions (that is, assumptions about the distribution of true
, excluding cases we visually identified as outliers. We used three different prior distributions (that is, assumptions about the distribution of true 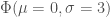 ), a diffuse uniform density between –1022 and 9288, and a spike-and-slab density with a 90% chance that
), a diffuse uniform density between –1022 and 9288, and a spike-and-slab density with a 90% chance that  40-50% larger in magnitude than their true values.
40-50% larger in magnitude than their true values. to match the published studies (though we did adjust sample sizes); consequently, our final results will likely change. Probably what we will do by the end is examine standardized marginal effects—viz., t-ratios—instead of nominal coefficient/marginal effect values; this technique has the advantage of folding variation in
to match the published studies (though we did adjust sample sizes); consequently, our final results will likely change. Probably what we will do by the end is examine standardized marginal effects—viz., t-ratios—instead of nominal coefficient/marginal effect values; this technique has the advantage of folding variation in 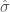 into a single parameter and requiring less per-study standardization (as t-ratios are already standardized). So I’m not yet ready to say that these are reliable estimates of how much the typical result in the literature is biased. As a preliminary cut, though, I would say that the results are concerning.
into a single parameter and requiring less per-study standardization (as t-ratios are already standardized). So I’m not yet ready to say that these are reliable estimates of how much the typical result in the literature is biased. As a preliminary cut, though, I would say that the results are concerning.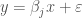 ,
, 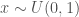 ,
,  . The true value of
. The true value of  has a 90% chance of being set to zero and a 10% chance of being drawn from
has a 90% chance of being set to zero and a 10% chance of being drawn from 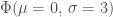 (this is the spike-and-slab distribution above). Consquently, the vast majority of DGPs are null relationships. Correctly-specified regression models
(this is the spike-and-slab distribution above). Consquently, the vast majority of DGPs are null relationships. Correctly-specified regression models 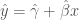 are estimated on each simulated sample. The observed (that is, published—statistically significant) and true, non-null distribution of standardized
are estimated on each simulated sample. The observed (that is, published—statistically significant) and true, non-null distribution of standardized 

 for a null hypothesis that beta is zero or negative. I argued that (despite our long pedagogical practice) there are, in fact, many situations where this interpretation of the p-value is actually the correct one (or at least close: it’s our rational belief about this probability, given the observed evidence).
for a null hypothesis that beta is zero or negative. I argued that (despite our long pedagogical practice) there are, in fact, many situations where this interpretation of the p-value is actually the correct one (or at least close: it’s our rational belief about this probability, given the observed evidence).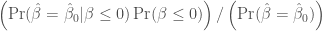 , or
, or  . Under the prior belief that all values of
. Under the prior belief that all values of  ; this is just the p-value (where we consider starting with the likelihood density conditional on
; this is just the p-value (where we consider starting with the likelihood density conditional on  , estimates a correctly specified regression on the data set, and records the estimated t-statistic on the estimate of beta. The plotted figure below shows the estimated conditional density of true beta values given
, estimates a correctly specified regression on the data set, and records the estimated t-statistic on the estimate of beta. The plotted figure below shows the estimated conditional density of true beta values given 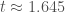 ; using Simpson’s rule integration, I calculated that the probability that
; using Simpson’s rule integration, I calculated that the probability that 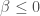 given
given 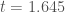 is 5.68%. This is very close to the theoretical 5% expectation for a one-tailed test of the null that
is 5.68%. This is very close to the theoretical 5% expectation for a one-tailed test of the null that 
 is just as probable as
is just as probable as 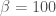 a priori.
a priori.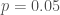 , the theoretical expectation). The distance between the solid and dotted line is the “bias” in the estimate of the probability that the null hypothesis is true; the p-value is almost always extremely overconfident. That is, seeing a p-value of 0.05 and concluding that there was a 5% chance that the null was true would substantially underestimate the true probability that there was no relationship between x and y.
, the theoretical expectation). The distance between the solid and dotted line is the “bias” in the estimate of the probability that the null hypothesis is true; the p-value is almost always extremely overconfident. That is, seeing a p-value of 0.05 and concluding that there was a 5% chance that the null was true would substantially underestimate the true probability that there was no relationship between x and y.
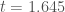 . But as the distribution becomes more and more diffuse, the p-value becomes a reasonably accurate approximation of the probability that the null is true.
. But as the distribution becomes more and more diffuse, the p-value becomes a reasonably accurate approximation of the probability that the null is true.
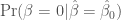 , which is natural since this is the sort of thing that an ordinary person wants to learn from an analysis and a p-value is a probability. And all these teachers, including me of course, have explained that
, which is natural since this is the sort of thing that an ordinary person wants to learn from an analysis and a p-value is a probability. And all these teachers, including me of course, have explained that 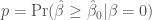 or equivalently
or equivalently 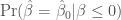 if you don’t like the somewhat unrealistic idea of point nulls.
if you don’t like the somewhat unrealistic idea of point nulls.
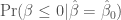 is
is  before this analysis, and thus specify an uninformative (and technically improper) prior
before this analysis, and thus specify an uninformative (and technically improper) prior  , the uniform distribution over the entire domain of
, the uniform distribution over the entire domain of  ,which is just the p-value (where we consider starting with the likelihood density conditional on
,which is just the p-value (where we consider starting with the likelihood density conditional on 
